Google is starting to support a number of microformats such as vCard and hReview. Google uses the term Rich Snippet for microformats.
This article shows by example how to use the hReview-aggregate format, which is ideal for sites dealing with ratings and reviews. Some well known examples of sites already incorporating the hReview format are Imdb, Rotten Tomatoes and Cnet.
As an example of how to use the hReview-aggregate format, we use a community driven site concerned with reviews of auto repair shops. On this site, each auto repair shop has a main page with its contact information and reviews written by users of the site.
On each page we wish to put a hReview markup, so that search engines and other software agents can parse the name of the shop being reviewed, its average rating and the number of user reviews.
The following PHP function writes a hreview-aggregate snippet based on a name of the auto repair shop and an array of reviews submitted by users.
It first loops through the reviews in order to obtain an average rating (one decimal place) and then the actual snippet is echoed in the RDFa format.
function create_hreview_aggregate($auto_repair_shop_name, $reviews)
{
$average_rating = 0.0;
$number_of_reviews = count($reviews);
if($number_of_reviews > 0) {
foreach ($reviews as $r)
{
$average_rating += intval($r->rating);
}
$average_rating = number_format($average_rating / $number_of_reviews, 1);
}
echo <<<EOT
<div style="display: none;" xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Review-aggregate">
<span property="v:itemreviewed">$auto_repair_shop_name</span>
<span rel="v:rating">
<span typeof="v:Rating">
Rating:
<span property="v:average">$average_rating</span>
/
<span property="v:best">5</span>
</span>
</span>
<span property="v:votes">$number_of_reviews</span>
<span property="v:count">$number_of_reviews</span>
</div>
EOT;
}
This code is placed on the main page for each auto repair shop in the database. If the page comes up in a Google search result, the name of the repair shop and the average rating will perhaps sometime appear just like movies on Imdb do today

Chances are that the snippet is just summarizing what is already visible to the human eye on the page. To avoid this redundancy, it is perfectly legal to hide the snippet.
This is what I have done in the example above by giving the div surrounding the snippet a “display: none” style.
Rich Snippets Testing Tool
At the moment, Google only supports Rich Snippets in its search results from a handfuld of major sites such as Imdb, Rotten Tomatoes and Cnet. If you are curious to see how Google interprets the semantic data on your site, you can use the Rich Snippets Testing Tool.
This is how the hReview-aggregate produced by the code above is interpreted by the tool:
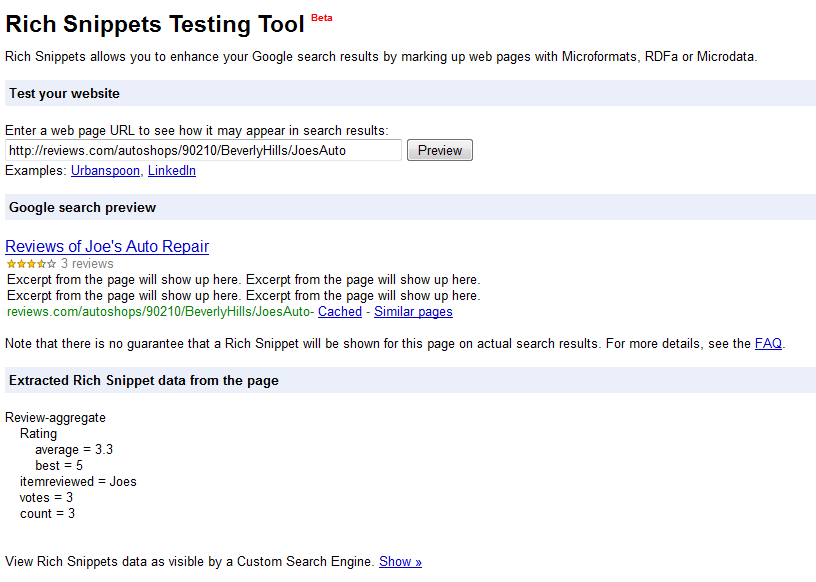
This tool also helps you in ensuring that your markup is syntactically correct. There is not much point in having semantic data on your page if it isn’t parsable by a machine after all :).
Another useful, non-Google tool for this purpose is Optimus.